What to do when you can’t find a coin

Mathematics, Sports, Statistics, and other things

What follows is the academic residue of a spirited discussion between a fellow PhD student and myself, concerning the use of measure theory in probability. The central question is “Why bother?” Here is my attempt at an answer to this question, through a small demonstration of measure theory’s ability to generalise. This is not an attempt to teach any measure theory, but I will point to a few resources at the end that I found helpful for reacquainting myself during our discussion if you would like to do the same.
First, we must establish in traditional terms the result we will later emulate measure-theoretically. I will only talk about non-negative random variables; the result generalises by splitting into positive and negative parts, but the notation is drastically simplified.
Theorem 1: If 



Proof:

There are two conceptually important points here. The less theoretically troublesome one is the switching of integrals, which Fubini lets us do, but I’ve always found a little cheeky. More foundationally important is that we assume the existence of a density
I will spare the majority of the details of satisfactorily defining a random variable measure-theoretically, but some objects need to be defined.
The premise of measure-theoretic probability is that we start with a measure space 







For our purposes, we can define any real-valued random variable as follows, by first defining the 
![\left(\left[0,1\right], \lambda\left(\left[0,1\right]\right), \mu \right)](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Cleft%5B0%2C1%5Cright%5D%2C+%5Clambda%5Cleft%28%5Cleft%5B0%2C1%5Cright%5D%5Cright%29%2C+%5Cmu+%5Cright%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
![\lambda\left(\left[0,1]\right]\right)](https://s0.wp.com/latex.php?latex=%5Clambda%5Cleft%28%5Cleft%5B0%2C1%5D%5Cright%5D%5Cright%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
![\left[0,1\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B0%2C1%5Cright%5D&bg=ffffff&fg=7f8c8d&s=0&c=20201002)


![U: \left[0,1\right] \to \left[0,1\right] ; U(\omega) = \omega](https://s0.wp.com/latex.php?latex=U%3A+%5Cleft%5B0%2C1%5Cright%5D+%5Cto+%5Cleft%5B0%2C1%5Cright%5D+%3B+U%28%5Comega%29+%3D+%5Comega&bg=ffffff&fg=7f8c8d&s=0&c=20201002)

Now, anyone familiar with the inverse-transform will know that defining any other real-valued random variable is a piece of cake. Every real-valued random variable 
![X : \left[0,1\right] \to \mathbb{R}; X(\omega) =F_X^{-1} \circ U(\omega) = F_X^{-1}(\omega)](https://s0.wp.com/latex.php?latex=X+%3A+%5Cleft%5B0%2C1%5Cright%5D+%5Cto+%5Cmathbb%7BR%7D%3B+X%28%5Comega%29+%3DF_X%5E%7B-1%7D+%5Ccirc+U%28%5Comega%29+%3D+F_X%5E%7B-1%7D%28%5Comega%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)

We are still missing one key element, expected value. We define it as 
Theorem 2: If
Proof:
If you’ll allow me a couple of pictures, I argue that it is true by definition. We see that the area integrated by 
![\int_{\left[0,1\right]} F^{-1} \mathop{d\mu}](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5Cleft%5B0%2C1%5Cright%5D%7D+F%5E%7B-1%7D+%5Cmathop%7Bd%5Cmu%7D&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
 .
.  .
. Q.E.D.
Now, we should be skeptical of any proof which follows so readily from the definitions. The traditional discrete distribution is marvelously intuitive. Further, we can squint at the traditional continuous expected value definition and notice the pattern. By comparison, the measure-theoretic definition is quite opaque. So far it seems like we just made up a definition so that this proof was easy. What’s the value in that? Here’s how I see it.
I liken it to the intermediate value theorem (IVT). The point of proving the IVT is not to dispel any doubt that if an arrow pierces my heart it must also have pierced my ribcage. The point of the IVT is in showing that the definition of mathematical continuity we have written down captures the same notion of physical and temporal continuity we sense in the real world.
What we have really learned from theorem 2 then, is that we can define expected value in terms of the probability function directly. We essentially drop the density assumption by fiat. The value is in discovering this more powerful definition which unites previously disparate discrete and continuous cases, as well as distributions which are a mix of both.
My favourite mixed distribution is the zero-inflated exponential, with probability function 


Traditionally, to evaluate an expected value we would have to be rather careful or apply some clever insight. Now with measure theory, we can ham-fistedly shove 
We can also start sparring with more exotic random variables on non-numeric spaces with confidence. I’m currently working through Diaconis’ Group Representations in Probability and Statistics, so hopefully I can speak on these “applications” in more detail in the future. But for now, I’ll leave it as an enticing mountaintop rather than trying to spoil the ending.
It is no secret that I don’t like the IVT, or theorem-motivated definitions more broadly, so I am uncomfortable leaning on it in an argument. What I will provide here is my own post-hoc intuition for the measure-theoretic expected value. Rather fortuitously it leans on the IVT, so I’ll point out pedantically that I’m actually using it as the Intermediate Value Property (IVP) in and of itself. Observe below that the area on the left is the area defining a measure-theoretic expected value as we have seen above.

Note that this area is the same as the area of the rectangular region. As it has unit width, its height is also its area. This height is not coincidentally the mean value of
In short, that generalisation is cool, and measure theory is not as scary as I thought after failing it in third-year. It gives us steady footing to go and explore exotic spaces, and it provides some nice perspectives on old favourites. Is it of practical use to the working statistician? Debateable. Our main theorem can certainly be used without actually doing any measure. Perhaps it provides nice perspectives on transformations if one does need to compute certain integrals which aren’t recognisable. What do you think? Have I convinced you measure-theoretic probability isn’t useless? Do you know any interesting applications I didn’t mention? As always, I’d love to hear your thoughts.
I am always hesitant to endorse texts based solely on how helpful they were to me. We should remember that one always understands something better the second time. That being said, the following two probability-oriented texts were useful to me. Matthew N. Bernstein has a trio of nice blog posts entitled Demystifying measure-theoretic probability theory, which are a nice, slow introduction to some of the basics. I also found Sebastien Roch’s Lecture Notes on Measure-theoretic Probability Theory useful as a much denser, more comprehensive reference. As for strictly measure-theoretic principles, I found plenty enough information by simply clicking the first Wikipedia article to pop up when I searched the relevant terms.

See mathsfeed.blog/problem-adding-dice-rolls/ for the motivation, introduction and immediate discussion of the problem.
We want to roll 



Let 






It might be that 
For a particular set of 

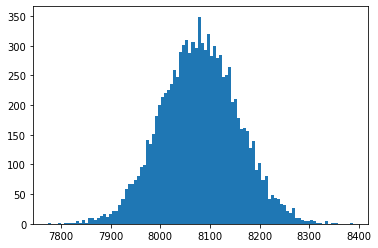
Here we can see a histogram for 10 000 samples of 
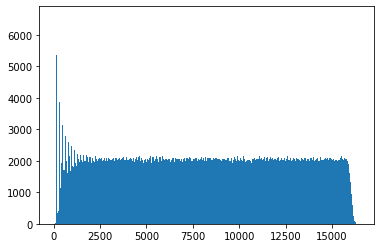
Here we see a histogram for 10 000 samples of 

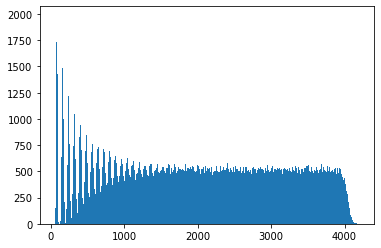
Here we only look at samples of 

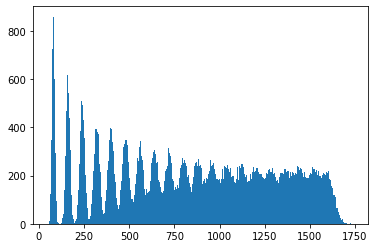
We can identify the spikes more clearly here. Given we roll 20 dice at a time, we should not be surprised to see the initial values occur in spikes about 70 units apart, which is roughly what we see.
They do get a bit wider as we move to the right, as the tails of slightly fatter and further right spikes gently nudge up their neighbours. So, whatever more technical answer we derive below should line up roughly with these observations, namely that by the time
For a more technical definition, you can be as picky as you like as to how you define suitably uniform, probably with some sort of 
If, for all 
Of course this is entirely heuristic, it is not longer obvious (in some sense) as long as there is more than one value 

It can be checked that 






is equal to one standard deviation below the mean for 
One can do some rather boring algebra to arrive at 









The definition of suitably uniform above is very heavily based in conditional probability, and I am a dyed-in-the-wool bayesian, so I’m going to attack with all the bayesian magic spells I can muster. If you’re a committed frequentist, maybe it’s time to look away.
We want to derive

Can we derive 

I know 

and we have no prior information about what 


Now admittedly it’s been a while since I was properly in the stats game, so my tools might be a bit rusty, but this doesn’t look like a pmf I’m familiar with. It looks like it’s in the exponential family, so maybe somebody with more experience in the dark arts can take it from here. I guess you could always figure out some sort of acceptance-rejection sampler if needed. Okay but what’s the point? Well now we have our posterior for 
Note of course that the normal approximation itself only works if the number of dice in each roll is suitably large to apply CLT. It also then feels like no coincidence that ‘about 30 rolls’ is the conclusion, as it sounds an awful lot like my usual usual retort when asked if a sample mean is big enough to make a normal approximation. Overall I’m okay with making approximations which assume a large
If you enjoyed this, you might enjoy my other posts on problems I would like to see solved, or find out more about my research from my homepage.

Last year, as part of the assessment for a machine learning course, we were asked to write a tutorial paper on a topic of our choice. I chose to write about Evolutionary Algorithms. I’m happy with how it turned out, and the lecturer chose it as an exemplar for future students. For posterity, I’m going to share it here. Unfortunately, the original .tex file is lost to the sands of time (more specifically, it was saved on a thumb drive that was the only casualty in a backpack-dropping accident while getting off the bus). Thus, the only copy I have access to is the PDF file that I submitted online. You can find that here:




You must be logged in to post a comment.