We want to roll dice at a time, and add up the total over repeated rolls, and continue to do so until we reach a threshold . When we reach or exceed , we note , the sum of the dice we just rolled. What is the distribution of ? We will call the range to the striking range, as a roll in this range might get us to . Inside this range we need to pay extra attention to the value of our dice roll, as depending on its value we might have to roll again, or we might have to stop.
Let be the cumulative sum of dice rolled times. Let be the cumulative sum of dice rolled an unknown number of times. We want to find a mixing point after which is uniform in terms of . Why? If we find such an , then as long as our threshold is at least a few maximum dice rolls away from , it doesn’t really matter how far away it is, we can always assume our cumulative total approaches the striking range from somewhere uniformly in an appropriately wide interval just outside the striking range. This significantly reduces the complexity of an analytic solution or a computer simulation. If the threshold is not significantly past the mixing point, then we have to be careful as our cumulative total is more likely to be at particular points, and the calculations become more complex, as our cumulative total will come in chunks of about at a time.
Does M exist?
It might be that doesn’t really exist, and there is always some very subtle nonuniformity to . This isn’t necessarily the case, but showing that would be another problem entirely, and we’re probably quite fine with technically a function of some tolerance level. Let’s quickly develop a mental picture with some histograms. This will hopefully convince us that exists (or we get close enough to uniform that it looks like exists), and how we might capture its meaning.
Pictures
For a particular set of and , just follows some discrete distribution with a nice bell-curvy shape. Of real interest is sampling from , as we don’t know how many rolls it took to reach our threshold. The immediate problem is this requires sampling a first, and we don’t want to have any assumption on ‘s value. So instead I will just uniformly sample values between 0 and 200 and hope that our brains can imagine the extension to unbounded . Play around with my code in the Colab notebook here. Actually, let’s always sample but keep track of the partial sum at each intermediate step. I know this technically violates independence assumptions, but whatever. I’m also going to work with for these pictures, as the results are suitably interesting.
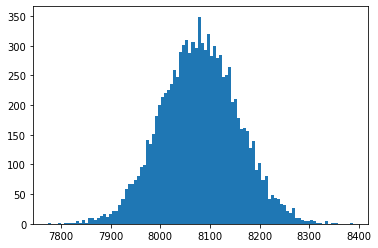
Here we can see a histogram for 10 000 samples of . As expected it forms a lovely bell-curve shape.
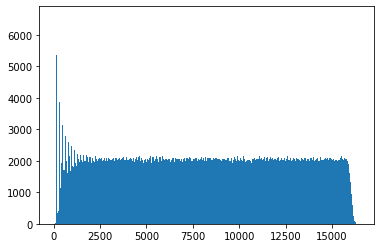
Here we see a histogram for 10 000 samples of for all . We can see the nice uniform property we’re looking for emerge definitively once exceeds about 3 000, but it’s hard to tell at this scale. Let’s zoom in on the more interesting part of the graph.
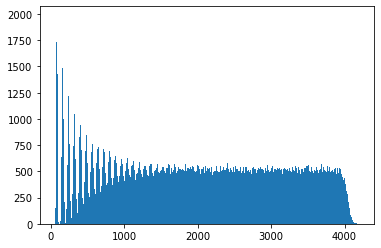
Here we only look at samples of for . We can see more clearly now the spikes which indicate we are not at the mixing point yet, which we can make out more clearly here is at about . Zooming in further:
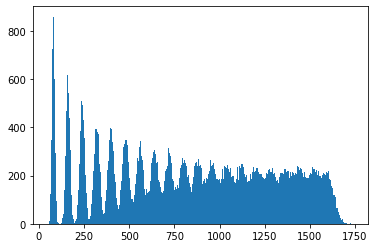
We can identify the spikes more clearly here. Given we roll 20 dice at a time, we should not be surprised to see the initial values occur in spikes about 70 units apart, which is roughly what we see.
They do get a bit wider as we move to the right, as the tails of slightly fatter and further right spikes gently nudge up their neighbours. So, whatever more technical answer we derive below should line up roughly with these observations, namely that by the time is about 2000, or about 29 dice rolls, it should be well mixed.
Defining M
For a more technical definition, you can be as picky as you like as to how you define suitably uniform, probably with some sort of floating around, but I want a rough and ready answer, and I don’t personally enjoy having ‘s littered throughout my work, so my working definition is as follows:
If, for all , it is no longer obvious to infer from how many rolls it took to reach , then is a mixing point.
Of course this is entirely heuristic, it is not longer obvious (in some sense) as long as there is more than one value for which is nonzero. This happens very quickly and does not capture what we see in the simulations. In the other direction, for any , there will always be some much more sensible guesses for than others, probably an integer close to . So we need to start by deciding on our criteria for obvious. I’ve come up with a couple of different definitions, and I’ll discuss them both below.
Finding M the easier way
It can be checked that , and that . From now on, if I need to, I will approximate with , a normal random variable with the same mean and variance. Then I can say we have reached the mixing point if there is significant overlap between and for some . Again there are lots of choices for what is meant by significant overlap and choice of . Inspired by mathsfeed.blog/is-human-height-bimodal I think a reasonable choice is to compare , and consider the overlap significant if the there is only one mode, not two. Using the fact that a normal pdf is concave down within 1 standard deviation of its mean, we would like that one standard deviation above the mean for :
is equal to one standard deviation below the mean for :
One can do some rather boring algebra to arrive at . You can solve this properly I guess, but I am a deeply lazy person, so I’m going to approximate the right-hand side as . If this upsets you, then I am deeply sorry, but I will not change. ( is big enough and we’re rounding to a whole number at the end of the day so its fine, but I’ve already spent more time justifying this than I wanted to.) This allows us to arrive at . This roughly agrees with the scale we wanted for . If you try and count out the first 21 spikes in the above plots, they become very hard to make out by the end. So I’m actually fairly happy with this answer, subject to some proper checking with more choices for and maybe just topping off with another 20% just for good measure. More important I think is convincing yourself that if I had chosen some other number of standard deviations or some larger , then as a function of should still be linear! So instead of rederiving all of these calculations, just remember that if you’re happy , is well-mixed, then , should be well-mixed too. Note that this condition truly isn’t enough to guarantee uniformity as it makes no attempt to consider the contribution of any other than and , but it should ensure any spikiness is rather muted. If you’re happy with this condition, good, so am I, but I may as well mention the other method I thought of for measuring mixing.
Finding M the bayesian way
The definition of suitably uniform above is very heavily based in conditional probability, and I am a dyed-in-the-wool bayesian, so I’m going to attack with all the bayesian magic spells I can muster. If you’re a committed frequentist, maybe it’s time to look away.
We want to derive
.
Can we derive ? Well by the definition of conditional probability,
.
I know is approximately normal, so
,
and we have no prior information about what should be, so we can treat with a constant uninformative prior. Finally, is not a function of , its just a scaling factor, so
.
Now admittedly it’s been a while since I was properly in the stats game, so my tools might be a bit rusty, but this doesn’t look like a pmf I’m familiar with. It looks like it’s in the exponential family, so maybe somebody with more experience in the dark arts can take it from here. I guess you could always figure out some sort of acceptance-rejection sampler if needed. Okay but what’s the point? Well now we have our posterior for , we can be more precise about it being suitably non-obvious what to infer for . The first criteria that come to mind for me is either specifying the variance should be suitably large (which can be approximated up to proportionality with the pdf, though that proportionality depends on generally), or that the mode of the distribution is suitably unlikely (also easy up to proportionality, but knowing the actual probability itself feels more integral to the interpretation). Of course in both cases we can approximation the proportionality constant by computing an appropriate partial sum. I’ve knocked up a quick demo on Desmos of what this would look like in practice.
Concluding remarks
Note of course that the normal approximation itself only works if the number of dice in each roll is suitably large to apply CLT. It also then feels like no coincidence that ‘about 30 rolls’ is the conclusion, as it sounds an awful lot like my usual usual retort when asked if a sample mean is big enough to make a normal approximation. Overall I’m okay with making approximations which assume a large for the same reason we are more interested in deriving results for large , namely for small and/or , we can probably simulate the answer with high precision using a computer, or even by hand for very small values. But these asymptotic results help us to be confident in when we can truncate the simulation for speed, or when we can stop doing simulations and rely only on the asymptotic results.
























































You must be logged in to post a comment.