
What follows is the academic residue of a spirited discussion between a fellow PhD student and myself, concerning the use of measure theory in probability. The central question is “Why bother?” Here is my attempt at an answer to this question, through a small demonstration of measure theory’s ability to generalise. This is not an attempt to teach any measure theory, but I will point to a few resources at the end that I found helpful for reacquainting myself during our discussion if you would like to do the same.
The traditional result
First, we must establish in traditional terms the result we will later emulate measure-theoretically. I will only talk about non-negative random variables; the result generalises by splitting into positive and negative parts, but the notation is drastically simplified.
Theorem 1: If 



Proof:

There are two conceptually important points here. The less theoretically troublesome one is the switching of integrals, which Fubini lets us do, but I’ve always found a little cheeky. More foundationally important is that we assume the existence of a density
In steps measure theory
I will spare the majority of the details of satisfactorily defining a random variable measure-theoretically, but some objects need to be defined.
The premise of measure-theoretic probability is that we start with a measure space 







For our purposes, we can define any real-valued random variable as follows, by first defining the 
![\left(\left[0,1\right], \lambda\left(\left[0,1\right]\right), \mu \right)](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Cleft%5B0%2C1%5Cright%5D%2C+%5Clambda%5Cleft%28%5Cleft%5B0%2C1%5Cright%5D%5Cright%29%2C+%5Cmu+%5Cright%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
![\lambda\left(\left[0,1]\right]\right)](https://s0.wp.com/latex.php?latex=%5Clambda%5Cleft%28%5Cleft%5B0%2C1%5D%5Cright%5D%5Cright%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
![\left[0,1\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B0%2C1%5Cright%5D&bg=ffffff&fg=7f8c8d&s=0&c=20201002)


![U: \left[0,1\right] \to \left[0,1\right] ; U(\omega) = \omega](https://s0.wp.com/latex.php?latex=U%3A+%5Cleft%5B0%2C1%5Cright%5D+%5Cto+%5Cleft%5B0%2C1%5Cright%5D+%3B+U%28%5Comega%29+%3D+%5Comega&bg=ffffff&fg=7f8c8d&s=0&c=20201002)

Now, anyone familiar with the inverse-transform will know that defining any other real-valued random variable is a piece of cake. Every real-valued random variable 
![X : \left[0,1\right] \to \mathbb{R}; X(\omega) =F_X^{-1} \circ U(\omega) = F_X^{-1}(\omega)](https://s0.wp.com/latex.php?latex=X+%3A+%5Cleft%5B0%2C1%5Cright%5D+%5Cto+%5Cmathbb%7BR%7D%3B+X%28%5Comega%29+%3DF_X%5E%7B-1%7D+%5Ccirc+U%28%5Comega%29+%3D+F_X%5E%7B-1%7D%28%5Comega%29&bg=ffffff&fg=7f8c8d&s=0&c=20201002)

We are still missing one key element, expected value. We define it as 
Theorem 2: If
Proof:
If you’ll allow me a couple of pictures, I argue that it is true by definition. We see that the area integrated by 
![\int_{\left[0,1\right]} F^{-1} \mathop{d\mu}](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5Cleft%5B0%2C1%5Cright%5D%7D+F%5E%7B-1%7D+%5Cmathop%7Bd%5Cmu%7D&bg=ffffff&fg=7f8c8d&s=0&c=20201002)
 .
.  .
. Q.E.D.
Some healthy skepticism
Now, we should be skeptical of any proof which follows so readily from the definitions. The traditional discrete distribution is marvelously intuitive. Further, we can squint at the traditional continuous expected value definition and notice the pattern. By comparison, the measure-theoretic definition is quite opaque. So far it seems like we just made up a definition so that this proof was easy. What’s the value in that? Here’s how I see it.
I liken it to the intermediate value theorem (IVT). The point of proving the IVT is not to dispel any doubt that if an arrow pierces my heart it must also have pierced my ribcage. The point of the IVT is in showing that the definition of mathematical continuity we have written down captures the same notion of physical and temporal continuity we sense in the real world.
What we have really learned from theorem 2 then, is that we can define expected value in terms of the probability function directly. We essentially drop the density assumption by fiat. The value is in discovering this more powerful definition which unites previously disparate discrete and continuous cases, as well as distributions which are a mix of both.
A concrete mixed distribution example
My favourite mixed distribution is the zero-inflated exponential, with probability function 


Traditionally, to evaluate an expected value we would have to be rather careful or apply some clever insight. Now with measure theory, we can ham-fistedly shove 
We can also start sparring with more exotic random variables on non-numeric spaces with confidence. I’m currently working through Diaconis’ Group Representations in Probability and Statistics, so hopefully I can speak on these “applications” in more detail in the future. But for now, I’ll leave it as an enticing mountaintop rather than trying to spoil the ending.
Intuition
It is no secret that I don’t like the IVT, or theorem-motivated definitions more broadly, so I am uncomfortable leaning on it in an argument. What I will provide here is my own post-hoc intuition for the measure-theoretic expected value. Rather fortuitously it leans on the IVT, so I’ll point out pedantically that I’m actually using it as the Intermediate Value Property (IVP) in and of itself. Observe below that the area on the left is the area defining a measure-theoretic expected value as we have seen above.

Note that this area is the same as the area of the rectangular region. As it has unit width, its height is also its area. This height is not coincidentally the mean value of
What have we learned?
In short, that generalisation is cool, and measure theory is not as scary as I thought after failing it in third-year. It gives us steady footing to go and explore exotic spaces, and it provides some nice perspectives on old favourites. Is it of practical use to the working statistician? Debateable. Our main theorem can certainly be used without actually doing any measure. Perhaps it provides nice perspectives on transformations if one does need to compute certain integrals which aren’t recognisable. What do you think? Have I convinced you measure-theoretic probability isn’t useless? Do you know any interesting applications I didn’t mention? As always, I’d love to hear your thoughts.
Resources
I am always hesitant to endorse texts based solely on how helpful they were to me. We should remember that one always understands something better the second time. That being said, the following two probability-oriented texts were useful to me. Matthew N. Bernstein has a trio of nice blog posts entitled Demystifying measure-theoretic probability theory, which are a nice, slow introduction to some of the basics. I also found Sebastien Roch’s Lecture Notes on Measure-theoretic Probability Theory useful as a much denser, more comprehensive reference. As for strictly measure-theoretic principles, I found plenty enough information by simply clicking the first Wikipedia article to pop up when I searched the relevant terms.

 dice at a time, and add up the total over repeated rolls, and continue to do so until we reach a threshold
dice at a time, and add up the total over repeated rolls, and continue to do so until we reach a threshold  . When we reach or exceed
. When we reach or exceed  to
to  the striking range, as a roll in this range might get us to
the striking range, as a roll in this range might get us to  be the cumulative sum of
be the cumulative sum of  times. Let
times. Let  be the cumulative sum of
be the cumulative sum of  after which
after which  is uniform in terms of
is uniform in terms of  . Why? If we find such an
. Why? If we find such an  at a time.
at a time.  . This isn’t necessarily the case, but showing that would be another problem entirely, and we’re probably quite fine with
. This isn’t necessarily the case, but showing that would be another problem entirely, and we’re probably quite fine with  but keep track of the partial sum at each intermediate step. I know this technically violates independence assumptions, but whatever. I’m also going to work with
but keep track of the partial sum at each intermediate step. I know this technically violates independence assumptions, but whatever. I’m also going to work with  for these pictures, as the results are suitably interesting.
for these pictures, as the results are suitably interesting. 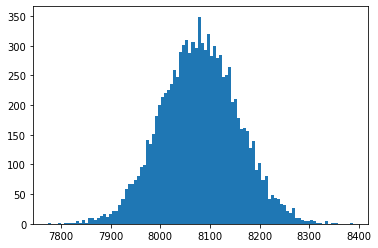
 . As expected it forms a lovely bell-curve shape.
. As expected it forms a lovely bell-curve shape. 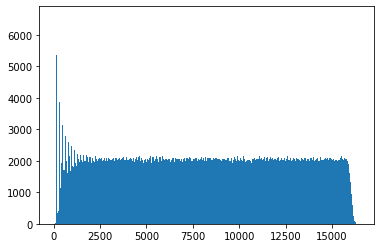
 for all
for all  . We can see the nice uniform property we’re looking for emerge definitively once
. We can see the nice uniform property we’re looking for emerge definitively once 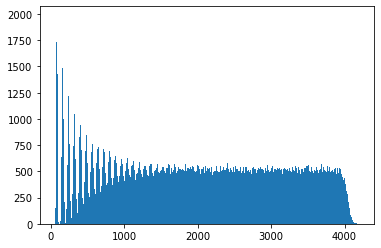
 . We can see more clearly now the spikes which indicate we are not at the mixing point yet, which we can make out more clearly here is at about
. We can see more clearly now the spikes which indicate we are not at the mixing point yet, which we can make out more clearly here is at about  . Zooming in further:
. Zooming in further: 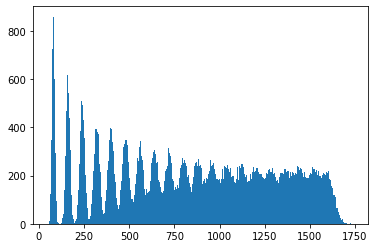
 floating around, but I want a rough and ready answer, and I don’t personally enjoy having
floating around, but I want a rough and ready answer, and I don’t personally enjoy having  , it is no longer obvious to infer from
, it is no longer obvious to infer from  is nonzero. This happens very quickly and does not capture what we see in the simulations. In the other direction, for any
is nonzero. This happens very quickly and does not capture what we see in the simulations. In the other direction, for any  . So we need to start by deciding on our criteria for obvious. I’ve come up with a couple of different definitions, and I’ll discuss them both below.
. So we need to start by deciding on our criteria for obvious. I’ve come up with a couple of different definitions, and I’ll discuss them both below.  , and that
, and that  . From now on, if I need to, I will approximate
. From now on, if I need to, I will approximate  , a normal random variable with the same mean and variance. Then I can say we have reached the mixing point if there is significant overlap between
, a normal random variable with the same mean and variance. Then I can say we have reached the mixing point if there is significant overlap between  for some
for some  . Again there are lots of choices for what is meant by significant overlap and choice of
. Again there are lots of choices for what is meant by significant overlap and choice of  . Inspired by
. Inspired by  , and consider the overlap significant if the there is only one mode, not two. Using the fact that a normal pdf is concave down within 1 standard deviation of its mean, we would like that one standard deviation above the mean for
, and consider the overlap significant if the there is only one mode, not two. Using the fact that a normal pdf is concave down within 1 standard deviation of its mean, we would like that one standard deviation above the mean for 
 :
: 
 . You can solve this properly I guess, but I am a deeply lazy person, so I’m going to approximate the right-hand side as
. You can solve this properly I guess, but I am a deeply lazy person, so I’m going to approximate the right-hand side as  . If this upsets you, then I am deeply sorry, but I will not change. (
. If this upsets you, then I am deeply sorry, but I will not change. ( . This roughly agrees with the scale we wanted for
. This roughly agrees with the scale we wanted for  ,
,  is well-mixed, then
is well-mixed, then  ,
,  should be well-mixed too. Note that this condition truly isn’t enough to guarantee uniformity as it makes no attempt to consider the contribution of any
should be well-mixed too. Note that this condition truly isn’t enough to guarantee uniformity as it makes no attempt to consider the contribution of any  other than
other than  and
and  , but it should ensure any spikiness is rather muted. If you’re happy with this condition, good, so am I, but I may as well mention the other method I thought of for measuring mixing.
, but it should ensure any spikiness is rather muted. If you’re happy with this condition, good, so am I, but I may as well mention the other method I thought of for measuring mixing.  .
.  ? Well by the definition of conditional probability,
? Well by the definition of conditional probability,  .
.  is approximately normal, so
is approximately normal, so 
 ,
, with a constant uninformative prior. Finally,
with a constant uninformative prior. Finally,  is not a function of
is not a function of  .
.  , we can be more precise about it being suitably non-obvious what to infer for
, we can be more precise about it being suitably non-obvious what to infer for 
You must be logged in to post a comment.